Let’s dive into the nuts and bolts of metadata technology so we can better understand what this information is, how it gets created, where it lives, and how to make use of it.
Schemas, fields and tags
A tag is a bit of information about a digital object. This could be the name of the creator, the location it was taken, a sentence describing what’s happening in a photo or any other relevant information. A tag lives in a field which gives you information about the tag itself. Is the tag “San Francisco” the location of the photo, or the address of the photographer? If it’s in the IPTC Location field, the tag refers to the place a photo was made. If it’s in the IPTC Author City field it refers to the address of the photographer. The figure below shows the relationship between schema, field, and tag.
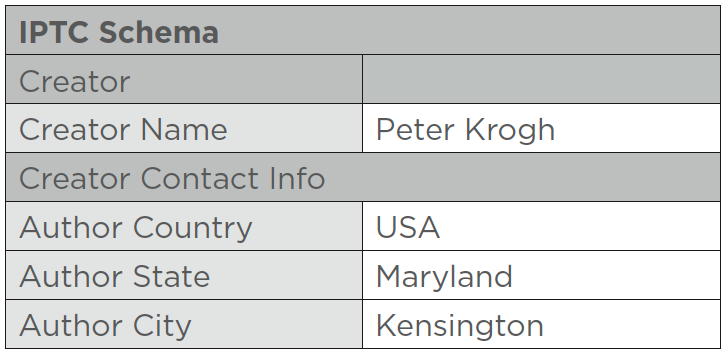
A schema is a system for structuring data. Inside a schema, a field namespace specifies the type of information and how it can be formatted. The tag is the actual bit of information. In this figure, we see a small portion of the IPTC schema. The creator name belongs to one part of the schema, and the address belongs to another set of tags.
Namespaces
A namespace describes the field and defines which kinds of tags are acceptable to put there — for example, “Write the name of the city where the photograph was created”. Namespaces will typically have a definition and a description of the allowable type of information to enter. Some are very strict, such as date fields which only accept entries formatted as dates, and some are very open, such as the Caption field, which will accept just about anything you want to type into it.
Schemas
A collection of namespaces is called a schema. Schemas are created to build structured metadata around a certain objective. This reflects the priorities of the schema creators and what’s important to them. Camera makers created the EXIF schema, newspaper companies created IPTC, while computer scientists and librarians created Dublin Core. Individual applications may also have their own schemas in order to write important information. Adobe has created several, including one to store Adobe Camera Raw settings and one to store Photoshop settings.
The universe is expanding
For the first few decades of digital imaging, the universe of schemas was pretty stable. In recent years, there has been quite a bit of growth in both the size and number of schemas. Digital images are now used by many industries for many different purposes.
Schemas are particularly useful for programmatic uses of images. Standardizing ways to write tags helps facilitate automatic processes. As media files become ever more useful for different purposes, we will continue to see schemas arise and evolve
Schema.org
Schema.org is an organization dedicated to creation, maintenance and interoperability of schemas. It is particularly focused on the way that schemas can help create shared understanding of meaning on the web. If you want to learn more (or just take a peek at the size of the schema universe) head over to their website.

Field Types
Namespaces can specify what kind of tags can be entered in a field. The restrictions (or lack of restrictions) are useful for different types of information. Understanding the type and number of tags allowed in a field helps you better understand how to tag your files correctly.
Number of items in a field
Namespaces will typically specify how many entries may appear in a particular field.
- Single value field - Many namespaces will permit only one entry. This is the case for the Author field, the Photographer Address fields, and the Copyright URL field. You could combine two photographers’ names into a single credit line if you needed to get around it, but the namespace treats this as a single entry.
- Multiple value field - Some fields can accept multiple independent entries. This is true of the Keywords field, and the Person Shown field. These are also known as “bag containers,” which we’ll see when we look at the XMP notation.
Types of allowable tags
In addition to the number of entries in a field, there will also be a specification for the type of tag that can be entered.
- Free text field - Some fields may allow you to enter any text you like. The Caption field will accept as much text as you care to type, along with web links or other formatted text.
- Controlled data type - Some fields require a specific type of data. The IPTC Creation Date field, for instance, requires that a precise date be entered, with an option of adding an exact time. The Copyright Statement URL specifies that only properly formatted web links are allowed.
- Controlled value field - A controlled value field limits entries to certain approved terms. The Mark as Copyrighted field only allows one of three values: Unknown, Copyrighted or Public Domain. Some controlled value fields may allow for multiple entries, e.g., a sports team may have a controlled list of player names to choose from, but allow for more than one player to be tagged in a photo.
Classes of metadata
The metadata we create and use falls into the following categories of useful but not absolute distinctions. For instance, the date/time a photo was made can be useful as both technical and descriptive metadata. Note that a particular schema may include fields from each of these categories.
- Technical - This describes the media object and encoding details. This can include pixel dimensions, color profile, etc.
- Descriptive - This tells us something about the subject matter depicted, such as the name of those pictured, the location shown, or concepts that the photo might illustrate.
- Administrative - These tags tell us something about the provenance, ownership and allowable use of a media file. This could include a usage rights statement, model release information or credit line text.
- Curatorial and Rendering - This is metadata that tells us how to make use of an image within a library or project. It also includes the rendering settings for parametric image editors.