Embedding metadata allows you to bundle it inside a file for portability, but sometimes embedded metadata can get stripped as files pass between services. Sometimes this is a conscious operation, either by the sender or by a middleman. Sometimes metadata stripping is an unintended side effect of a software configuration. Metadata can be stripped field by field, and can also be stripped entirely.
Intentional stripping upon export
There are valid reasons to want to strip metadata from files. The tags may expose information you wish to keep private, such as names or locations of people pictured. Files may contain stray metadata that was created by the supplier of the file which is confusing or irrelevant to your use of the file. The tags may be inaccurate. And it’s also possible that in some cases the size of the metadata in a file can be large enough that it increases the file size too much (although that’s pretty rare).
Controlling your output.
You may have private metadata in your database that is inappropriate to share with others. When you want to keep these tags private, you’ll need to remove it from exported or transferred files, either automatically (if possible) or manually (if necessary). Shown below are two metadata export dialogs in Adobe software that give you control over what gets embedded.
By default, Adobe generally passes along all metadata. The primary exception in Photoshop is in the Save for Web (Legacy) dialog. It allows you to choose classes of metadata to preserve (and thus classes of metadata to strip.) A decade ago, the default for Save for Web was to remove all metadata, including ownership and credit info. Adobe responded and changed the settings to preserve this information by default.
In Adobe Lightroom Classic, there is also an option to remove certain metadata. You will notice that Lightroom Classic does not offer the ability to remove copyright info on output (a strong request from its photographer community.) You can also see that both person and location information are stripped by default, even when you have asked to export all metadata. This is configured to address privacy concerns, including some that are part of international law. The Lightroom user must intentionally choose to include this information or it will be excluded.
Stripping by web services
When media files are uploaded to web services – particularly social media services – it’s common for most or all metadata to be stripped. This can be intentional or unintentional. It’s important to understand that most images uploaded to web services are going to be recompressed, and an entirely new file is made. We’re used to Photoshop passing along embedded metadata, but that’s not always the case with the software that powers web services.
Most web services use open source software like ImageMagick for image handling. When ImageMagick is installed, preservation of metadata may not be enabled. The site’s developers need to know to turn it on, and then they need to actually do so. I know that in some services, metadata preservation is simply an oversight. In some others, I suspect that it’s done intentionally. As with the Lightroom export mentioned above, this could be done in order to protect privacy. It might also be done to remove ownership information.
YOU MIGHT BE WONDERING…
Why can’t I lock metadata?
If metadata is so valuable, shouldn’t you be able to lock it to the file? Shouldn’t Adobe or somebody just make it so that metadata is permanent and can’t be stripped away? I hate to be the bearer of bad news, but it’s just not possible. Existing software and file formats don’t support locking, and there’s no magical way to make them do that.
You could theoretically lock metadata by making a new file format that is unsupportable by current software, but that makes it impossible to convert to a TIFF or JPEG. This hypothetical new format would be a pretty tough sell. I don’t think many people would be willing to use a file format that could never be converted to the universally accessible formats already in use. It’s possible to add security to PDF files so that they must be opened with a key. However, once you open the PDF, it’s possible to save the image in whatever format you wish, so metadata is ultimately no more secure for PDF images, once they are in use.
Bottom line: you need to check
If you want to be sure that metadata is not stripped in an application or web service, you’ll need to do some actual testing. Send a file through the process and then open it in a good file browser like Adobe Bridge or PhotoMechanic. This will let you examine the metadata to see if it’s been stripped or preserved, as shown below.
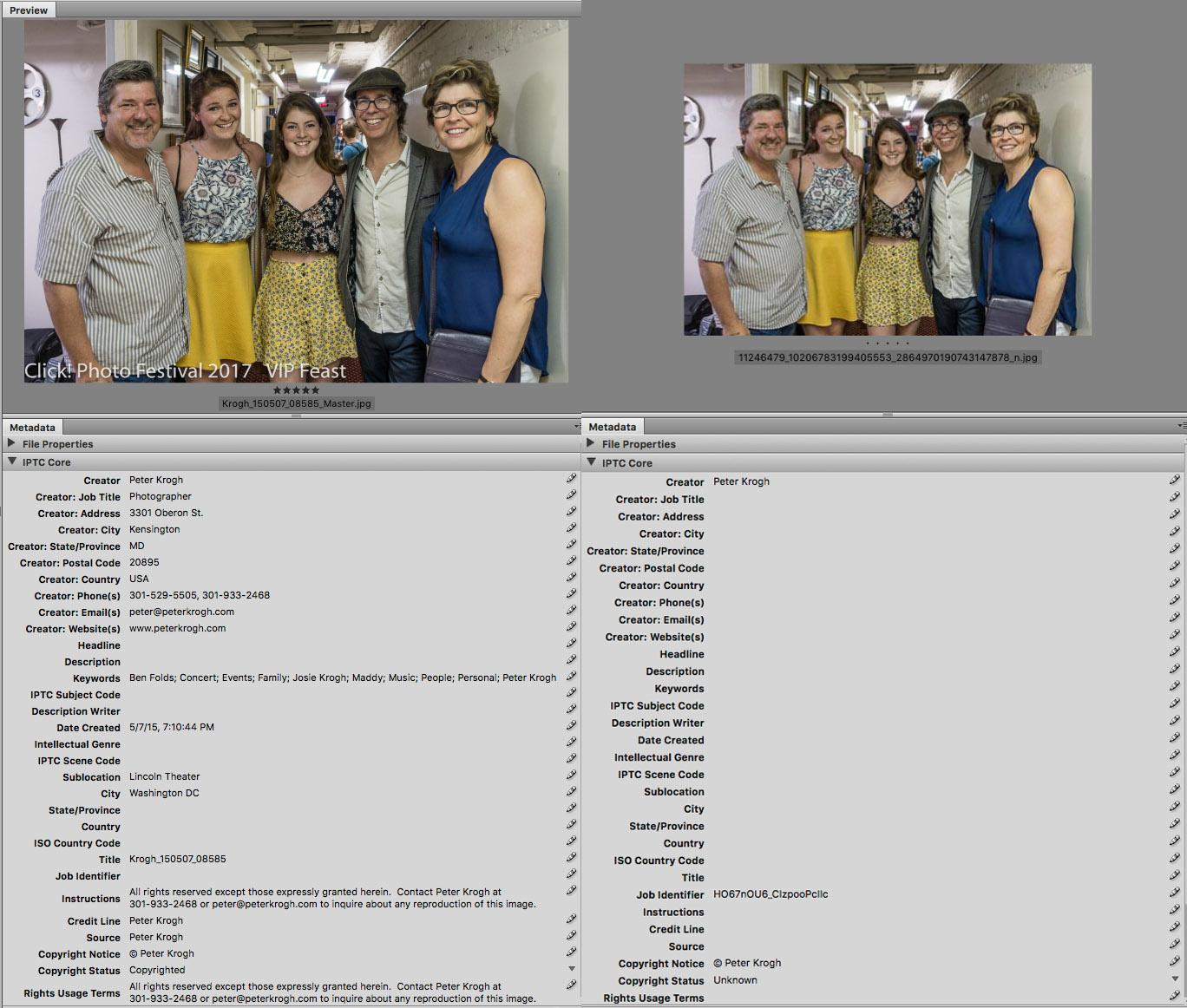
Here is a file before upload to Facebook and after download from Facebook. As you can see, only minimal metadata has been preserved. Facebook will preserve the photographer name and copyright notice, but everything else is gone.
There are other methods of interchange which require some level of integration. These are usually built on APIs and will make use of metadata that is transmitted in a language built for that purpose. We’ll take a look at those methods a bit later.